
Потоковая вычислительная архитектура
Данный сайт посвящен новой вычислительной архитектуре сигнальных процессоров, управляемых потоком данных.
I. Введение
Актуальность разработки вычислительных архитектур на базе потоковой (data-flow) парадигмы не вызывает сомнений, поскольку потенциально они могут обеспечить существенно большую производительность по сравнению с традиционной фон-неймановской архитектурой. Тем не менее, эффективная реализация потоковых архитектур (ПА) наталкивается на целый ряд серьезных проблем, таких как: реализация рекурсии, циклов, итераций, работа с константами и др.
В ряде зарубежных экспериментальных проектов, проводившихся с начала 1980-х до середины 2000-х годов, в которых разрабатывались динамические потоковые (ДП) архитектуры, не нашлось эффективных путей решения перечисленных проблем (смотри работы: J.Gurd, C.Kirkham, and I.Watson. The Manchester prototype dataflow computer. Commun. ACM, 28(1), Jan. 1985. P. 34-52; Arvind, and R.S. Nikhil. Executing a program on the MIT tagged token dataflow architecture. IEEE Trans. Comput., 39(3), Mar. 1990. P. 300-318; K. Hiraki, S. Sekiguchi, and T. Shimada. Status report of SIGMA1: A dataflow supercomputer. In J.L.Gaudiot and L.Bic, editors. Advanced Topics in DataFlow Computing, chapter 7, Prentice Hall, Englewood Cliffs, New Jersey, 1991. P. 207-224). Недостатки, присущие ДП-архитектурам:
● Аппаратная сложность и время сравнения тегированных маркеров в Памяти сравнения достаточно высоки. Максимально возможная производительность архитектуры достижима при реализации Памяти сравнения в виде ассоциативной памяти. Однако большой объем памяти, необходимый для хранения ожидающих маркеров, делает этот подход проблематичным.
● Степень параллельности в выполняемых программах не контролируется. Ряд приложений может генерировать больше параллельных действий, чем позволяют аппаратные возможности архитектуры. Результат – снижение реальной производительности.
● Последовательные участки кода исполняются неэффективно. Потери времени на этих участках из-за сравнения тегированных маркеров, их обмена, формирования и доступа к различным структурам запоминающего устройства (ЗУ) не всегда могут быть скомпенсированы одновременной обработкой потоков данных на параллельных участках кода.
● Отсутствие ограничения числа одновременно выполняемых итераций цикла и контекста процедуры ведет к увеличению размера тегов, потерь времени на их коммуникацию по сети и объема аппаратуры.
● Большое разнообразие типов памяти – Память совпадений, Память переполнения (блок отложенных маркеров), Память программ и констант, Память очереди тегированных маркеров и другие – усложняет управление памятью.
● Невозможно использовать регистровые структуры с такой же эффективностью, как в обычной многопроцессорной системе.
Эффективное решение этих и других не указанных проблем возможно только на базе быстрой и емкой ассоциативной памяти, которая при этом будет наиболее аппаратно- и энергозатратным ресурсом, что целесообразно только для систем массового параллелизма.
В России серьезные результаты в области разработки универсальных высокопроизводительных систем, использующих принцип управления потоками данных, были достигнуты коллективом под руководством академика Бурцева В.С. (см., например, Бурцев В.С. Параллелизм вычислительных процессов и развитие архитектуры супер-ЭВМ. М.: Торус Пресс, 2006. 203 p.). После кончины академика Бурцева В.С. и перехода большей части его коллектива из ИПИ РАН в ИППМ РАН работы по совершенствованию потоковой архитектуры были продолжены уже там.
Попытки использования потоковой парадигмы в области цифровой обработки сигналов также имеют многолетнюю историю (смотри следующие работы: Sundararajan Sriram. Minimizing Communication and Synchronization Overhead in Multiprocessors for Digital Signal Processing. Ph.D. Dissertation, Dept. of EECS, Technical Report UCB/RL 95/90, University of California, Berkeley, CA 94720, October, 1995. 187 p; M.Chase. A Pipelined Data Flow Architecture for Digital Signal Processing: The NEC ?PD7281. IEEE Workshop on Signal Processing, November 1984; Iiro Hartimo. DFSP: A Data Flow Signal Processor. IEEE Transactions on Computers, v. C-35, N 1, January 1986. P. 23-33; K. Kronlof, J. Skytta, 0. Simula, I. Hartimo. Simulation of a digital signal processing architecture based on the data flow principle. Proc. ISCAS’82, Rome, Italy, May 10-12, 1982. P. 1053-1056). Авторы указанных работ отмечают, что принципы ПА и требования со стороны алгоритмов ЦОС хорошо сочетаются друг с другом в приложениях, для которых характерна высокая степень внутреннего параллелизма. Основными сдерживающими факторами широкого практического использования такой интеграции являются высокая цена многопроцессорных реализаций и потери производительности при внекристальной реализации коммуникационной межпроцессорной сети. Для большинства приложений ЦОС динамическое распределение данных излишне, т.к. предсказуемость времени исполнения программы обеспечивает жизнеспособность статических методов их распределения.
В Институте проблем информатики Федерального исследовательского центра «Информатика и управление» РАН была разработана концепция принципиально новой многоядерной потоковой рекуррентной архитектуры (МПРА). Архитектура изначально разрабатывается как специализированная, предназначаемая для реализации параллельных вычислительных процессов (ВП) обработки сигналов в реальном времени. Она базируется на рекуррентно-динамической вычислительной парадигме, которую можно рассматривать как развитие парадигмы потока данных, но построенной на другом принципе, а именно — на принципе самодостаточных, рекуррентно сжатых данных (РД).
II. Особенности организации вычислительного процесса в МПРА
Предлагаемая архитектура нетрадиционна и радикально отличается по основным моментам не только от классической архитектуры фон Неймана, но и от других нетрадиционных параллельных архитектур, в частности, от архитектур, работающих по принципу потока данных (data-flow).
Для существующих традиционных и нетрадиционных компьютерных архитектур характерно наличие двух потоков: потока инструкций и потока данных.
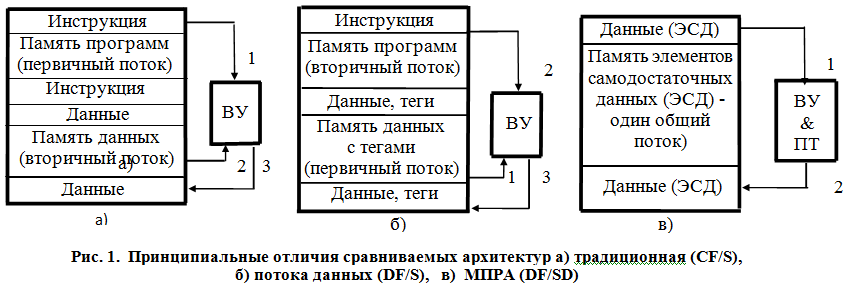
В МПРА оба потока сливаются в один общий поток самодостаточных данных, в котором, помимо собственно обрабатываемых данных, содержится и необходимая для их обработки управляющая и служебная информация. Наглядное представление о сравнительных качествах рассматриваемых архитектур дает их сопоставление на рис. 1 и 2 (приводятся для наглядности):
— по организации памяти и инициации вычислительного процесса (рис. 1);
— по количеству шагов, необходимых для выполнения инструкции (рис. 2).
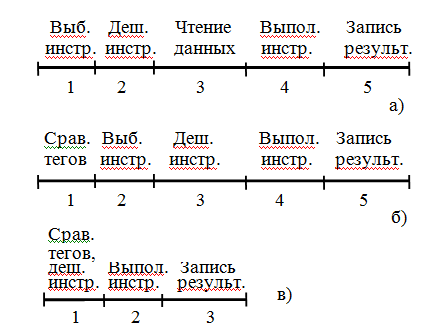
а) — в) — идентичны значениям на рис. 1
Для потоковых архитектур (DF — Data-Flow) сохраняется разделение ресурсов памяти на две области. Однако статус памяти данных меняется — из пассивной (вторичной) она превращается в активную (первичную), — цифра 1 на рис. 1,б, — в ячейках которой хранятся данные (операнды) с дополнительными функциональными полями (тегами). Как правило, функциональные поля содержат в себе информацию об исполнительном адресе инструкции (микрокоманды), которая должна быть извлечена из памяти программ для выполнения требуемых действий над поступившими на обработку компонентами пары (цифра 2 на рис. 2,б). Полный объем привлекаемых инструкций также хранится в статическом виде.
МПРА относится к классу потоковых архитектур, причем в отличие от них тегируемые данные являются самодостаточными, т.к. они содержат всю информацию по их обработке: информацию о компоненте пары по обработке; о команде, которая должна быть выполнена над парой, и о месте назначения результата операции. Результат операции может быть: оставлен в конкретном ВУ для последующего использования, передан другим ВУ по коммуникационной сети, сохранен в памяти ЭСД в качестве промежуточного результата для повторного использования, передан во внешнюю среду в качестве окончательного результата.
Данные являются самодостаточными не только для текущего шага обработки. Они также содержат начальную сжатую информацию, которая определяет содержание тегов результата в процессе их рекуррентных преобразований, в том числе с учетом вариативности условий формирования этого результата.
В разрабатываемой архитектуре в состав ВУ включено автономное устройство преобразования тегов (ПТ), которое обладает возможностью саморазвертки рекуррентного ВП. Устройство ПТ инициируется операндами, пришедшими на обработку в ВУ, работает параллельно с ВУ и определяет действие на следующем шаге ВП (модифицирует теги). Устройство ПТ представляет собой относительно простую (по аппаратным затратам) комбинационную схему, содержащую средства настройки (в необходимых случаях) на предметную область.
В памяти МПРА нет исполняемой программы в традиционном смысле. Есть только начальные значения тегов операндов, которые динамически подвергаются рекуррентной саморазвертке устройствами ПТ (отсюда название архитектуры DF/SD – Data Flow/ Static Dynamic). Для выполнения алгоритма необходимо задать начальные значения функциональных тегов. Представленная подобным образом в МПРА программа была названа капсулой.
Для получения искомого результата в CF/S выполняется последовательность действий 1-5 (см. рис. 2). Число шагов в DF/S не меняется. В архитектуре DF/SD оно уменьшается до логически необходимого минимума — 3; уменьшается также суммарный объем требуемых ресурсов памяти и число пересылок между функциональными устройствами ЭВМ. Если уменьшение числа шагов в МПРА до 4 — очевидно: необходимость выборки инструкции отсутствует, то возможность совмещения в одном шаге сравнения тегов и дешифрации инструкции будет показана ниже при рассмотрении структуры рекуррентного обрабатывающего устройства (РОУ).
III. Комбинированнный двухуровневый вариант реализации МПРА
Исторический опыт разработки компьютерных архитектур свидетельствует (смотри Arvind. The Evolution of Dataflow Architecture from Static Dataflow to P-RISC. Proc. of Workshop on Massive Parallelism: Hardware, Programming and Application, Amalfi, Italy, October 1989. Academic Press, 1990), что новая архитектура может потерпеть неудачу по следующим причинам:
• если она базируется на чрезвычайно сложных аппаратных механизмах для поддержки предназначенной ей модели программирования;
• если она игнорирует совместимость с существующими вычислительными средами;
• если она игнорирует проблему программируемости.
Результаты работ по различным вариантам исполнения РОУ убедительно свидетельствуют, что она не требует сложных аппаратных механизмов для поддержки присущей ей капсульной модели программирования. Что касается второго положения, то характер работ в рамках РОУ и не предполагает достижения совместимости с существующими вычислительными средами. Наоборот, он предполагает разработку уникальной вычислительной среды, в максимальной степени, учитывающей специфику МПРА.
Поиск компромиссного решения, включающего в себя совместимость с существующими вычислительными и аппаратными средами, возможен при удовлетворении определенных требований. В первую очередь, это требование поддержки потокового характера вычислительного процесса, реализуемого в РОУ.
Реализация такого подхода возможна на базе гибридного варианта рекуррентного обработчика сигнала (ГАРОС): процессора с сокращенным набором команд NIOS2 и ПЛИС с организацией Programmable Logic Device (PLD) в рамках семейства микросхем фирмы Altera под условным названием Stratix IV (Волчек В.Н., Степченков Ю.А., Петрухин В.С., Прокофьев А.А. Цифровой сигнальный процессор с нетрадиционной рекуррентной потоковой архитектурой // Проблемы разработки перспективных микро- и наноэлектронных систем — 2010. Сборник трудов / под общ. ред. академика А.Л.Стемпковского. М.:ИППМ РАН, 2010. С. 412-417) (см. рис. 3).
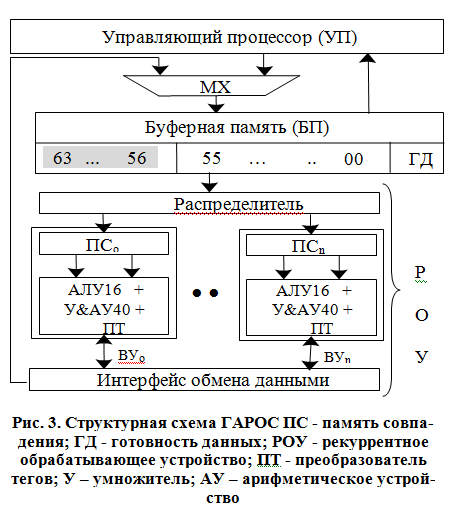
В структуру ГАРОС входят: управляющий процессор (УП) на базе фон-неймановской архитектуры, распределитель, четыре однотипных рекуррентных вычислительных устройства (ВУ) и интерфейс межпроцессорного обмена — исполнительный уровень гибридного РОС. В свою очередь, каждое ВУ состоит из: памяти совпадения (ПС), вычислителя (на базе 16-разрядного АЛУ и умножителя с накоплением МАС) и преобразователя тегов (ПТ).
В качестве устройства сопряжения УП и РОУ (поток данных между ними носит интенсивный характер) предлагается использовать специальный тип двухпортовой буферной памяти (БП), реализованного в ПЛИС. Одновременное чтение капсулы из одного порта и запись результатов операции в другой порт предположительно позволит сбалансировать поток данных между управляющим процессором и четырьмя операционными процессорными устройствами.
На управляющий уровень ГАРОС возлагается выполнение процедур предварительной подготовки капсул, реализацию последовательных частей исполняемой программы и запись результатов в один порт БП. Операционный уровень РОС обеспечивает считывание капсул, готовых для исполнения; параллельные вычисления в ВУ и запись результатов вычислений в другой порт. Введение в состав РОС двухпортовой БП, позволит также исключить потери времени на перемещение данных между двумя уровнями архитектуры ГАРОС.
Буферная память предназначена для хранения шаблонов капсул. В режиме обмена данными с РОУ происходит одновременное чтение и запись (со стороны РОУ) в БП, благодаря двухпортовой реализации ЗУ. Память признаков (готовность данных, ГД) контролирует наличие данных в шаблонах капсул. Если данные в БП готовы для считывания, то в бит ГД по данному адресу заносится ‘1′, иначе – ‘0’. При обмене данными БП с РОУ возникает необходимость одновременного изменения признаков по двум адресам (обнуление для считанных данных, и выставление ‘1’ для принятых). Двухпортовая организация БП обеспечивает одновременную запись в порт 1 и чтение из порта 2 или одновременную запись в порт 1 и порт 2.